Introduction
An
as yet un-documented aspect of the Oracle Traffic Director 11.1.1.7
(OTD) new features, has introduced the ability to operate a highly
available load balancing group within the Infiniband fabric but
keeping to a minimum usage of the root account. In previous releases to enable the high availability features of the failover group it was necessary for a couple of the OTD running processes to be run with the root privileges, this was something that security conscious customers found disconcerting.
This blog posting is courtesy of one of my colleagues, Mark Mundy who has been pulling together some instructions on how to setup OTD in an HA configuration and using minimal root user privileges.
Why
is root needed at all?
Before
we can demonstrate how we can minimise the use of root in an HA OTD
set up it is worth explaining a little of where OTD requires root
permission. This will hopefully give the reader an appreciation of
why it is used and even in a minimal use scenario how little ‘damage’
using it to execute part of the process stack can do.
Oracle
Traffic Director provides support for failover between the instances
in a failover group by using an implementation of the Virtual Routing
Redundancy Protocol (VRRP), this being keepalived for Linux.
Keepalived
v1.2.2 is included in the current Exalogic Guest Base Template and so
you do not need to install or configure it. Oracle Traffic Director
uses only the VRRP subsystem. If you wish to discover more about
keepalived go to http://www.keepalived.org. (If you are using Solaris then the implementation is done using the Solaris vrrpd service.)
VRRP
specifies how routers can failover a VIP address from one node to
another if the first node becomes unavailable for any reason. The IP
failover is implemented by a router process running on each of the
nodes. In a two-node failover group, the router process on the node
to which the VIP is currently addressed is called the master. The
master continuously advertises its presence to the router process on
the second node. Only the root user can start or stop this keepalived
process which controls the VIP and so without root permission having
a highly available VIP would not be possible.
With the 11.1.1.7 release of OTD it is possible to
configure a highly available VIP utilising keepalived and root
however all other processes associated with OTD such as the instance,
the primordial and watchdog will be executed as a non root user. No
user data is exposed to the keepalived process.
Example
OTD configuration
There
are a number of ways that Oracle Traffic Director can be deployed and
utilised but for the purposes of this example the simplest and most
common approach has been adopted. This design utilises the Exalogic
Storage Array for all of the OTD collateral utilising a number of
shares within the same project. The design consists of three
identical vServers created all with the same vServer type and
networking capability. The diagram below should give an idea of the
layout of both the vServers and what they are hosting as well as how
they are utilising various shares on the storage array. Notice that
the Admin Server and Admin Node 1 are using OTD binaries from one
share while the Admin Node 2 uses a different one. This will ensure
if there is a need to patch OTD it can be done with a degree of
availability while this is happening. There is one share for the
entire OTD configuration in this example.

The
2 vServers hosting admin nodes work as local proxies for the OTD
administration server and it is on these nodes that the highly
available instances will perform the actions as designed within the
loadbalancing configuration. In previous releases of OTD with this
setup it was possible to avoid using root to run the administration
server but the admin nodes that run an HA loadbalanced instance
required root for a large part, if not all, of their administration
and execution. In the latest release this has changed and it is this
that is exploited in this example.
Configuring
the Admin Server node
The
first vServer that needs to be configured is the one hosting the
administration server. There is no need to use the root account on
this vServer after the specific shares that are needed by OTD have
been permanently mounted. This note will not go into the details of
how this is achieved as it is assumed the reader is familiar with
this. The first share that is required to be temporarily
mounted is the /export/common/general share available on the Exalogic
storage array. This needs to be mounted and the OTD 11.1.1.7
installer placed in a directory within it (available from Oracle
edelivery) and unzipped. An example being
/mnt/common/general/OTD11117/Disk1.
This can then be un-mounted when OTD
has been installed. There is also a need to permanently mount two
shares one for the binaries and another for the configurations.
/export/OTDExample/Primary_Install
-> /u01/OTD
/export/OTDExample/OTDInstances
-> /u01/OTDConfiguration
|
In
this example the user chosen to install and run the Admin Server is
the pre-configured oracle user and so ensure that the share mount points
are owned by the oracle user on the ZFS appliance. (See my earlier blog posting about creating shares on the ZFS appliance.)
There
is now no additional need to utilise the root account on this
vServer. Everything in this section should now be performed as the
oracle user or an equivalent non privileged user of your choice.
For
simplicity the OTD installer will be installed using a silent
installer approach below is an example of how this can be achieved.
$ oracle@OTDAdminServer
~]$ /mnt/common/general/OTD11117/Disk1/runInstaller -silent
-waitforcompletion -invPtrLoc /home/oracle/oraInst.loc
ORACLE_HOME=/u01/OTD/ SKIP_SOFTWARE_UPDATES=TRUE |
The
ORACLE_HOME location is where the OTD binaries will be laid down and
this will populate the primary binary location on the share. The
invPtrLoc will need to point to a previously created file called
oraInst.loc which should contain the location of the Oracle
Inventory. In this example this file contains the following:
$ cd /home/oracle
$ cat oraInst.log
inventory_log=/home/oracle/oraInventory
$ |
For
more information on silently installing Oracle Traffic Director refer
to the documentation
Once
the installation is complete the OTD admin server can be created and
started. To create the admin server the following command can be
used:
$ oracle@OTDAdminServer
~]$ /u01/OTD/bin/tadm configure-server --user=admin
--java-home=/u01/OTD/jdk/ --instance-home=/u01/OTDInstances/ |
When
this is executed you will be prompted to provide an OTD admin user
password of your choice and then the admin server will be created
with its home directory under the /u01/OTDInstances share called
admin-server
The
admin server can now be started with the following command
$ oracle@OTDAdminServer
~]$ /u01/OTDInstances/admin-server/bin/startserv |
When
the admin server has started it will be possible as the output will
note, to access the admin console from a browser.
Log
in and create a new test configuration of your choosing and provide a
fake origin server so as to complete the configuration. This is only
to demonstrate and the configuration can be later deleted to be
replaced with a production one created. Do not deploy the
configuration at this stage. Leave the admin console open and for the
test configuration enable the plain text report in the virtual server
monitoring section. This is done so as to later give us an idea that
everything is working as expected in terms of the HA element of OTD.
This
completes the work to get the admin server operational and as you can
see in terms of OTD no use of the root privilege to configure, start
or stop.
Configuring
the Admin nodes
The
admin nodes now need to be created and started and this is where with
earlier releases of OTD there was a heavier requirement for the root
account. The new release needs far less and this is demonstrated here
by the fact that in order to minimise root use it is now possible to
create and start and stop admin nodes without root. In this section
we will do this.
Setup the first Instance node
After
logging on to the first of the admin nodes (OTDNode1) as root there
is an initial requirement to set up permanent shares to both the
primary OTD install location and the configuration as there was with
the admin server. These shares are the same as were mounted for the Administration Server. The mounting of these shares are the only time you require root access for this section.
Using
a non privileged account such as the pre-configured oracle account
you can now create an admin node and register it with the admin
server previously created and started. Prior to running the command
ensure the following.
Create
a sub-directory under /u01/OTDInstances with the hostname of this
vServer
Ensure
that the admin server hostname is resolvable on the private IPoIB
vNet in the /etc/hosts file
Ensure
that the admin node host name is resolvable in the admin server
/etc/hosts file on the IPoIB private vNet created
The
following example command will show the creation of the admin node.
$ /u01/OTD/bin/tadm configure-server --user=admin
--java-home=/u01/OTD/jdk/ --instance-home=/u01/OTDInstances/OTDNode1
--server-user=oracle --admin-node --host=OTDAdminServer |
The
share primary binary location is used to launch the command and you
will notice that the admin node server-user is the non privileged
oracle user. After providing the admin password and accepting the
self signed certificate the admin node should be created.
It
is now possible to start the admin node using the startserv script located in the OTDNode1 bin directory.
Note previously in order to utilise an HA OTD configuration this
would need to be executed as root or as a user in the sudoers list.
Setup the Second Instance Node
Now
that the first admin node is running it is possible to do the same
with the second admin node.
Before
the admin node can be created and started it needs to install OTD
into the secondary binary location using a variation of the silent
install for the admin server. This will mean mounting temporarily the
/export/common/general share and then using the same kit to install
OTD to the Secondary_Install share.
The
second admin node should have the following shares mounted
permanently
/export/OTDExample/Secondary_Install
-> /u01/OTD
/export/OTDExample/OTDInstances
-> /u01/OTDConfiguration
|
Thus the second instance will run binaries from a separate install from the other instances but the running configuration is located under the same share.
Prior
to running the create command ensure the three pre-requisites as
above are complete then you can run as an example
$ /u01/OTD/bin/tadm configure-server --user=admin
--java-home=/u01/OTD/jdk/ --instance-home=/u01/OTDInstances/OTDNode2
--server-user=oracle --admin-node --host=OTDAdminServ
|
One
created the second admin node can be started using the startserv script under the OTDNode2 instance directory.
Deploying
a basic configuration
The
next step is to utilise the admin console or indeed the command line
to deploy the current basic configuration and create instances of it
on the 2 admin nodes already running. This will not mean we have a
highly available loadbalancing pattern but will at this stage mean we
have 2 instances hosting the loadbalancing configuration that can be
independently accessed on the public EoIB ip addresses assigned to
each of the vServers when they were created. We will use the admin
console to firstly ensure the 2 admin nodes are available and running
and then to deploy the configuration to them both.
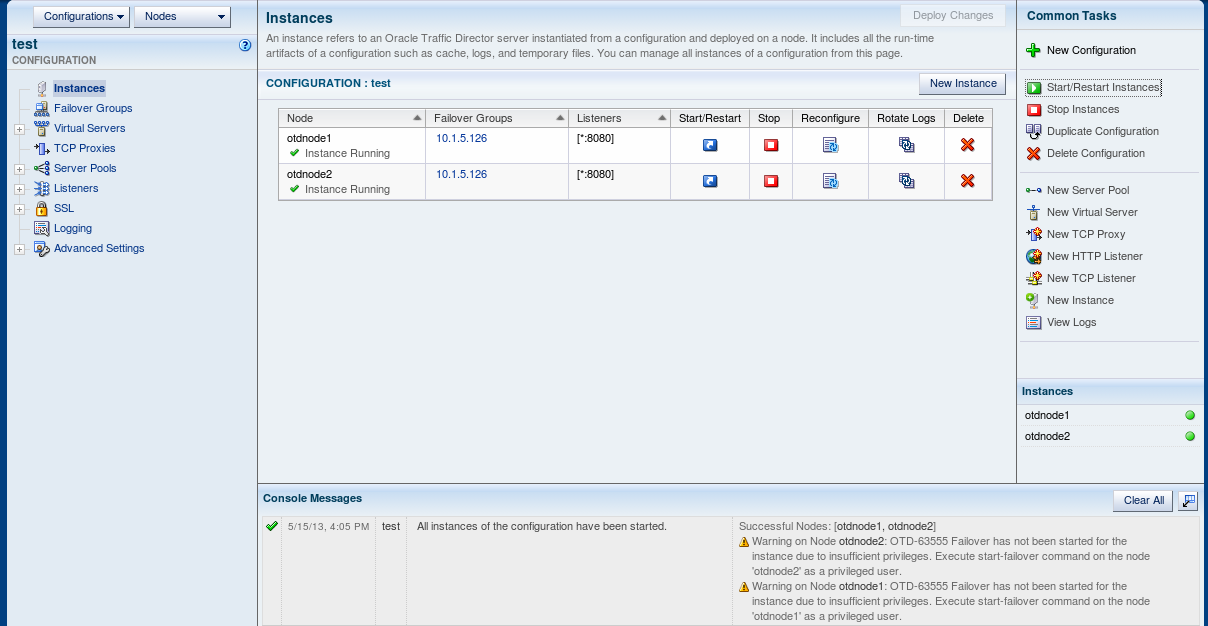
Here
we can see we have 2 operational admin nodes with no instances
deployed to them.
By
hitting the deploy button to the top right and selecting the 2 otd
admin nodes and NOT the admin server we can deploy the configuration
and have 2 instances created one on each node.
The
instances can now be started from the admin console. To verify the 2
instances are working it is possible in separate browser tabs to
access the instance on the public EoIB ip address assigned to it and
get performance metrics from it. An example url is shown below and by using the IP address for each of the instances then metrics from both instances will be displayed.
| http://<OTDNode1-EoIB-IP>
:8080/.perf |
At
this stage it is also possible to verify that the entire OTD process
tree for an admin node is all executing as the non privileged user as
this example shows:
oracle
19808 0.0 0.0 25648 812 ? Ss May14 0:00
trafficd-wdog -d /u01/OTDInstances/OTDNode1/admin-server/confi
oracle
19809 0.0 0.3 149568 15156 ? S May14 0:17 \_
trafficd -d /u01/OTDInstances/OTDNode1/admin-server/config
oracle
19810 0.1 3.5 769996 141768 ? Sl May14 1:23 \_
trafficd -d /u01/OTDInstances/OTDNode1/admin-server/co
oracle
19897 0.0 0.0 11560 968 ? Ss May14 0:00 \_
/u01/OTD/lib/Cgistub -f /tmp/admin-server-4baa05d0
oracle
12508 0.0 0.0 11560 340 ? S 02:13 0:00
\_ /u01/OTD/lib/Cgistub -f /tmp/admin-server-4baa
oracle
12609 0.0 0.0 25648 812 ? Ss 02:16 0:00
trafficd-wdog -d /u01/OTDInstances/OTDNode1/net-test/config -r
oracle
12610 0.3 0.3 135016 12232 ? S 02:16 0:00 \_
trafficd -d /u01/OTDInstances/OTDNode1/net-test/config -r
oracle
12611 0.0 0.5 259904 23304 ? Sl 02:16 0:00 \_
trafficd -d /u01/OTDInstances/OTDNode1/net-test/config
|
Creating
a failover group
Now
we need to create a failover group to enable the configuration
deployed to be made highly available. It is at this point that there is still a
requirement to use the root privilege. The first stage in enabling an
HA loadbalancing configuration is to create a failover group. This
does not require root permission to create, however it will need root
permission to activate. Creating a failover group can be done either
via the command line or the admin console. For this example we will
use the command line. From any of the three vServers log in as the
oracle user and issue the following example command to create a new
failover group within the configuration already created and active.
[oracle@OTDAdminServer
~]$/u01/OTD/bin/tadm create-failover-group --config=test
--virtual-ip=<ip_on_public_EoIB --primary-node otdnode1
--backup-node=otdnode2 --router-id=230 --verbose --port=8989
--user=admin --host=OTDAdminServer --network-prefix-length=21
Enter
admin-user-password>
OTD-63008
The operation was successful on nodes [otdnode1, otdnode2].
Warning
on node 'otdnode2':
OTD-67334
Could not start failover due to insufficient privileges. Execute the
start-failover command on node 'otdnode2' as a privileged user.
Warning
on node 'otdnode1':
OTD-67334
Could not start failover due to insufficient privileges. Execute the
start-failover command on node 'otdnode1' as a privileged user.
|
The
failover group is created however you will see that 2 warnings are
given. This is because although the non privileged user can create a
failover group, it does not have permission to start the keepalived
process. In our scenario the 2 instances are already running and so
this warning is generated. This is the first of the changes in
11.1.1.7 to be encountered. The new command start-failover allows
only what is required to be started as root to be performed
separately. In order to complete the ability to run OTD in an HA
configuration the command needs to be run as root or as a non
privileged user who is part of the sudoers list locally on each of
the admin nodes. This warning would not be seen if the instances were
not already running but if an attempt was made to start an instance
as a non privileged user in a failover group a warning would be
issued about the need to start the failover group separately.
In
order to minimise the use of root the preferred way to issue the
start-failover command is via the non privileged user after adding it
to the sudoers list. The specific permission required to allow this
is as follows for the non privileged user and in this case we use the
oracle user.
# cat /etc/sudoers | grep oracle
oracle
ALL=(root) /u01/OTD/bin/tadm |
To
set this up as root on each of the 2 admin nodes execute visudo and add the line to give the oracle user the privilege to run the tadm command.
Once
this has been set up the start-failover command can be issued locally
on each of the admin node vServers as this example shows.
$ sudo /u01/OTD/bin/tadm start-failover
--instance-home=/u01/OTDInstances/OTDNode1 --config=test
[sudo]
password for oracle:
OTD-70198
Failover has been started successfully |
It
is now possible from a browser to access the text based performance
statistics as before but on the public vip assigned to the HA OTD
configuration. A quick look at the process tree for an OTD admin node
will now show what this new command has done.
oracle
19808 0.0 0.0 25648 812 ? Ss May14 0:00
trafficd-wdog -d /u01/OTDInstances/OTDNode1/admin-server/config -r
/u01/OTD -t /tmp/admin-server-4baa05d0 -u orac
oracle
19809 0.0 0.3 149568 15156 ? S May14 0:17 \_
trafficd -d /u01/OTDInstances/OTDNode1/admin-server/config -r
/u01/OTD -t /tmp/admin-server-4baa05d0 -u oracl
oracle
19810 0.1 3.5 770244 142548 ? Sl May14 1:26 \_
trafficd -d /u01/OTDInstances/OTDNode1/admin-server/config -r
/u01/OTD -t /tmp/admin-server-4baa05d0 -u o
oracle
19897 0.0 0.0 11560 968 ? Ss May14 0:00 \_
/u01/OTD/lib/Cgistub -f /tmp/admin-server-4baa05d0/.cgistub_19810
oracle
12508 0.0 0.0 11560 340 ? S 02:13 0:00
\_ /u01/OTD/lib/Cgistub -f /tmp/admin-server-4baa05d0/.cgistub_19810
oracle
12857 0.0 0.0 25648 808 ? Ss 02:25 0:00
trafficd-wdog -d /u01/OTDInstances/OTDNode1/net-test/config -r
/u01/OTD -t /tmp/net-test-b92c33b1 -u oracle
oracle
12858 0.0 0.3 135016 12236 ? S 02:25 0:00 \_
trafficd -d /u01/OTDInstances/OTDNode1/net-test/config -r /u01/OTD -t
/tmp/net-test-b92c33b1 -u oracle
oracle
12859 0.0 0.5 259908 23308 ? Sl 02:25 0:00 \_
trafficd -d /u01/OTDInstances/OTDNode1/net-test/config -r /u01/OTD -t
/tmp/net-test-b92c33b1 -u oracle
root
12986 0.0 0.0 35852 504 ? Ss 02:29 0:00
/usr/sbin/keepalived --vrrp --use-file
/u01/OTDInstances/OTDNode1/net-test/config/keepalived.conf --pid
/tmp/net-
root
12987 0.0 0.0 37944 1012 ? S 02:29 0:00 \_
/usr/sbin/keepalived --vrrp --use-file
/u01/OTDInstances/OTDNode1/net-test/config/keepalived.conf --pid
/tmp/root 12987 0.0 0.0 37944 1012 ? S 02:29 0:00
\_ /usr/sbin/keepalived --vrrp --use-file /u01/OTDInstances/O
|
As
you can see, now only the keepalived processes are running as root
with everything else run as oracle. In previous releases a lot more
of the process tree would have been run as root in order to achieve
the same thing.
Starting
and stopping the instances hosting the failover group
There
are some important points to note around how with a minimal root use
set up loadbalancing instances are stopped and started. As the
previous section described, with an instance in a failover group,
there is a requirement to start the failover element as a privileged
user. It is still possible either through the admin console or via
the command line to start an instance non privileged, however a
warning will be generated in the console messages to remind the
administrator to explicitly start the nodes associated keepalived
configuration as a privileged user only if started through the admin
console. Until this is done the vip is not operational.
It
is important to note that if starting via the CLI the instance will
start but no warning about explicitly starting the failover
group will be given and this means that an administrator could think
the HA vip was working when it will not be. In any scripted startup
it is important to ensure after starting the instance the
start-failover command is issued locally to each of the instances in
the group.
Stopping
an instance is also a two stage process, as an instance attempted to
be stopped via a non privileged user either through the admin console
or the CLI will fail until the associated failover group on the node
on which it is running is stopped. This can be shown by the following
examples.
From
the admin console attempting to stop instances before stopping the
failover group.
From
the CLI attempting to stop an instance.
$ /u01/OTDInstances/OTDNode1/net-test/bin/stopserv
[ERROR:32]
server is not stopped because failover is running. Before stopping
the server, execute stop-failover command as a privileged user
|
For
either approach, prior to stopping the instance, there is a need to
run the stop of the failover group locally as a privileged user as
seen below.
$ sudo /u01/OTD/bin/tadm stop-failover
--instance-home=/u01/OTDInstances/OTDNode1 --config=test
|
It
is worth pointing out however that the number of times an instance
needs to be stopped and restarted is minimal due to the way most of
the configuration changes made are dynamically applied to an
instance. By utilising the administration console or including in CLI
based configuration changes the ‘reconfig-instance’ command stops
and starts can be minimised.
Changing
the primary failover instance
The
situation may arise where there is a need to ‘flip’ the current
owner of the OTD HA vip to the backup node. One such occasion being a
possible maintenance window and ordinarily this would be achieved by
issuing the ‘Toggle Primary’ button in the admin console or the
tadm set-failover-group-primary command. These are still applicable
and can be initiated by a non privileged user however there is an
additional step that needs to be performed from the CLI locally on
the admin nodes.
If
you use the admin console to toggle the primary you will see a
warning generated however the console will acknowledge the new
primary group member.
Testing
to see if the backup is now primary by accessing it will show that
the existing primary is still the primary, despite the console
saying otherwise.
Similarly
if the switch is made using the CLI the following warning is given
but after the warning the administration ‘thinks’ the switch has
been made.
$ /u01/OTD/bin/tadm set-failover-group-primary --config=test
--virtual-ip=10.1.5.126 --primary-node=otdnode2 --user=admin
--host=OTDAdminServer
Enter
admin-user-password>
OTD-63008
The operation was successful on nodes [otdnode1, otdnode2].
Warning
on node 'otdnode2':
OTD-67335
Could not restart failover due to insufficient privileges. Execute
the start-failover command on node 'otdnode2' as a privileged user.
Warning
on node 'otdnode1':
OTD-67335
Could not restart failover due to insufficient privileges. Execute
the start-failover command on node 'otdnode1' as a privileged user.
$ /u01/OTD/bin/tadm list-failover-groups --config=test --user=admin
--port=8989 --host=OTDAdminServer --all
Enter admin-user-password>
10.1.5.126
otdnode2 otdnode1
|
In
order to actually make the toggle active the failover group needs to
be restarted and this will force a re-read of the keepalived.conf
which will ensure the vip is plumbed up on the new primary host. This
command needs to be executed as the privileged user on both
instances. It is therefore paramount to ensure that if there is a
need to toggle the primary vip host that this two stage process is
carried out.
[oracle@OTDNode2
~]$ sudo /u01/OTD/bin/tadm stop-failover
--instance-home=/u01/OTDInstances/OTDNode2 --config=test
[sudo]
password for oracle:
OTD-70201
Failover has been stopped successfully.
[oracle@OTDNode2
~]$ sudo /u01/OTD/bin/tadm start-failover
--instance-home=/u01/OTDInstances/OTDNode2 --config=test
OTD-70198
Failover has been started successfully.
|
Deleting
a failover group
Deleting
a failover group is also now with minimal root usage, a two stage
process that needs to be understood. If you decide to delete a
failover group from the admin console or the CLI and the instances in
the failover group are running then although the console and the CLI
will allow a non privileged user to delete the group, a warning will
be generated to alert that the failover group has not been stopped.
The keepalived.conf will be removed; however the vip will still be
active. It will only be destroyed once the stop-failover command has
been executed locally by the privileged user on all instances
of the failover group. It is important to realise this and
perform the 2 operations close together to ensure that when removing
a failover group the vip associated is stopped as well.
Here
is an example of the warning in the admin console.
Known
Issues
There
is a known issue currently outstanding with Oracle Traffic Director
that will cause issues if after initial configuration, the
administration server is stopped and restarted and the node names
chosen to be used in the deployment contain any upper case letters.
The issue manifests itself in the admin console where messages like
the following are seen ‘Error
in parsing configuration TechDemoMWConfig. OTD-63763 Configuration
'test' has not been deployed to node 'OTDNode1'’.
After this any attempts to subsequently modify the configuration
will fail. This is a bug resolved in a later release and so to
workaround this for now there are 2 choices.
Use
only lowercase node names for the configuration
Log
in as the non privileged user to the administration server vServer
and edit the ‘../config-store/server-farm.xml’
for the administration server node and convert the node names to all
lowercase – eg otdnode1. Save the file and then restart the
administration server.
Setting
up manually simple init.d scripts for vServer start/stop
Because
none of the nodes has been configured or executed as root, the new
feature available in 11.1.1.7.0 to automatically create init.d
startup/shutdown services is not available. Therefore in order to
have both nodes and instances start and stop cleanly when a vServer
is shutdown or started, manually created and configured /etc/init.d
scripts need to be put in place. This clearly requires the use of the
root account but is a one off exercise to set up. Here we show an
example that can be used to give at least a rudimentary start/stop
script for your OTD minimal root privilege environment. These scripts
are far less rich in terms of functionality than those provided by
the product.
For
the administration server node only one init.d script is required to
be created and in this example this is called otd-admin-server.
An example can be seen here that can be tailored to suit a specific
environment:
#!/bin/sh
#
#
Startup script for the Oracle Traffic Director 11.1.1.7
#
chkconfig: 2345 85 15
#
description: Oracle Traffic Director is a fast, \
#
reliable, scalable, and secure solution for \
#
load balancing HTTP/S traffic to servers in \
#
the back end.
#
processname: trafficd
#
ORACLE_HOME="/u01/OTD"
OTD_USER=oracle
INSTANCE_HOME="/u01/OTDInstances/AdminServer"
INSTANCE_NAME="admin-server"
PRODUCT_NAME="Oracle
Traffic Director"
OTD_TADM_SCRIPT=/tmp/otd_script
case
"$1" in
start)
COMMAND="$INSTANCE_HOME/admin-server/bin/startserv"
su
- $OTD_USER -c $COMMAND
echo
"$ORACLE_HOME/bin/tadm start-snmp-subagent --instance-home
$INSTANCE_HOME" > ${OTD_TADM_SCRIPT}
chmod
755 ${OTD_TADM_SCRIPT}
su
- $OTD_USER -c ${OTD_TADM_SCRIPT}
rm
-f ${OTD_TADM_SCRIPT}
;;
stop)
echo
"$ORACLE_HOME/bin/tadm stop-snmp-subagent --instance-home
$INSTANCE_HOME" > ${OTD_TADM_SCRIPT}
chmod
755 ${OTD_TADM_SCRIPT}
su
- $OTD_USER -c ${OTD_TADM_SCRIPT}
rm
-f ${OTD_TADM_SCRIPT}
COMMAND="$INSTANCE_HOME/admin-server/bin/stopserv"
su
- $OTD_USER -c $COMMAND
;;
status)
ps
-ef | grep $INSTANCE_NAME
;;
*)
echo
$"Usage: $0 {start|stop|status}"
exit
1
esac
|
Once
saved and made executable with a chmod
+x.
Issuing
the following as root within the /etc/init.d directory will configure
the script to be started and stopped appropriately as the vServer is.
| # chkconfig
otd-admin-server on |
On
each of the admin nodes, 2 scripts need to be created so as to be
able to stop the highly available instance and failover group
independently of the admin node.
For
the admin nodes create a script in the /etc/init.d directory called
otd-admin-server and tailor the example below to reflect your
environment:
#!/bin/sh
#
#
Startup script for the Oracle Traffic Director 11.1.1.7
#
chkconfig: 2345 85 15
#
description: Oracle Traffic Director is a fast, \
#
reliable, scalable, and secure solution for \
#
load balancing HTTP/S traffic to servers in \
#
the back end.
#
processname: trafficd
#
ORACLE_HOME="/u01/OTD"
OTD_USER=oracle
INSTANCE_HOME="/u01/OTDInstances/OTDNode1"
INSTANCE_NAME="admin-server"
PRODUCT_NAME="Oracle
Traffic Director"
OTD_TADM_SCRIPT=/tmp/otd_script
case
"$1" in
start)
COMMAND="$INSTANCE_HOME/admin-server/bin/startserv"
su
- $OTD_USER -c $COMMAND
echo
"$ORACLE_HOME/bin/tadm start-snmp-subagent --instance-home
$INSTANCE_HOME" > ${OTD_TADM_SCRIPT}
chmod
755 ${OTD_TADM_SCRIPT}
su
- $OTD_USER -c ${OTD_TADM_SCRIPT}
rm
-f ${OTD_TADM_SCRIPT}
;;
stop)
echo
"$ORACLE_HOME/bin/tadm stop-snmp-subagent --instance-home
$INSTANCE_HOME" > ${OTD_TADM_SCRIPT}
chmod
755 ${OTD_TADM_SCRIPT}
su
- $OTD_USER -c ${OTD_TADM_SCRIPT}
rm
-f ${OTD_TADM_SCRIPT}
COMMAND="$INSTANCE_HOME/admin-server/bin/stopserv"
su
- $OTD_USER -c $COMMAND
;;
status)
ps
-ef | grep admin-server
;;
*)
echo
$"Usage: $0 {start|stop|status}"
exit
1
esac
|
Now
create a second script on each of the admin nodes this time called
otd-net-test for the highly available instance and again this
example can be tailored to suit your environment. The name being
based is the configuration the instance is hosting:
#!/bin/sh
#
# Startup script for the Oracle Traffic Director 11.1.1.7
# chkconfig: 2345 85 15
# description: Oracle Traffic Director is a fast, \
# reliable, scalable, and secure solution for \
# load balancing HTTP/S traffic to servers in \
# the back end.
# processname: trafficd
#
ORACLE_HOME="/u01/OTD"
OTD_USER=oracle
INSTANCE_HOME="/u01/OTDInstances/OTDNode1"
INSTANCE_NAME="net- TechDemoMWConfig"
PRODUCT_NAME="Oracle Traffic Director"
OTD_TADM_SCRIPT=/tmp/otd_script
case "$1" in
start)
COMMAND="$INSTANCE_HOME/$INSTANCE_NAME/bin/startserv"
su - $OTD_USER -c $COMMAND
echo "$ORACLE_HOME/bin/tadm start-failover --instance-home $INSTANCE_HOME --config=TechDemoMWConfig" > ${OTD_TADM_SCRIPT}
chmod 755 ${OTD_TADM_SCRIPT}
$OTD_TADM_SCRIPT
rm -f ${OTD_TADM_SCRIPT}
;;
stop)
echo "$ORACLE_HOME/bin/tadm stop-failover --instance-home $INSTANCE_HOME --config=TechDemoMWConfig" > ${OTD_TADM_SCRIPT}
chmod 755 ${OTD_TADM_SCRIPT}
$OTD_TADM_SCRIPT
rm -f ${OTD_TADM_SCRIPT}
COMMAND="$INSTANCE_HOME/$INSTANCE_NAME/bin/stopserv"
su -$OTD_USER -c $COMMAND
;;
status)
ps -ef | grep $INSTANCE_NAME
;;
*)
echo $"Usage: $0 {start|stop|status}"
exit 1
esac
|
Note
these scripts not only stop and start the instance and admin nodes,
the instance one also ensures that the failover group is started as
the root privileged user. It is also worth pointing out that there is
an additional command to start and stop the SNMP sub-agent, this is
optional and only required if it is the intention to have, at a later
date your OTD estate to be monitored via an Enterprise Manager 12C
agent.
Once
the 2 scripts are complete, as root, the chkconfig
<script_name> on
command can be executed to enable them.
The
new services can be tested by running the following as the root user
on each of the vServers in turn to see that the OTD estate stops and
then restarts.
service
otd-net-test stop
service
otd-admin-server stop
service
otd-admin-server start
service
otd-net-test start
|
When
complete it will be possible to stop any one of the vServers and
maintain a load balancing capability and when restarted the OTD
components on the vServer will automatically restart on startup.
Utilising
this note you will now have a highly available Oracle Traffic
Directory configuration that is only using the root privilege where
it is strictly required to do so.



















{kind=link}